
Hoy queremos explicarles cómo rastrear el indexamiento de PDF’s sensibles y bloquear su acceso al robot de Google. ¿No tienes ni idea de lo que estamos hablando?
Vamos a dar un ejemplo:
Había una vez un cliente que vendía cursos por internet. Como contaba con una mala programación del sitio, los robots de Google indexaban PDF’s internos con las clases de esos cursos. ¿Cuál es el problema? Bueno, las ventas del cliente disminuían: los PDF’s deberían administrarse a los usuarios como una respuesta a sus consultas, y la intención (obviamente) era que paguen por ellos. Cualquier persona podía buscar el PDF en Google y descargarlo gratuitamente.
Con este ejemplo, podemos sacar tres conclusiones:
- Los PDF’s logran buena posición.
- Una mala programación del sitio puede provocar una disminución de ventas.
- Hay que tener cuidado con las herramientas que trackean posiciones: si no revisamos qué URL está registrando, podríamos considerar que vamos por buen camino cuando en realidad estamos tirando dinero a la basura.
No todo es Big Data a la hora de bloquear la indexación de PDF
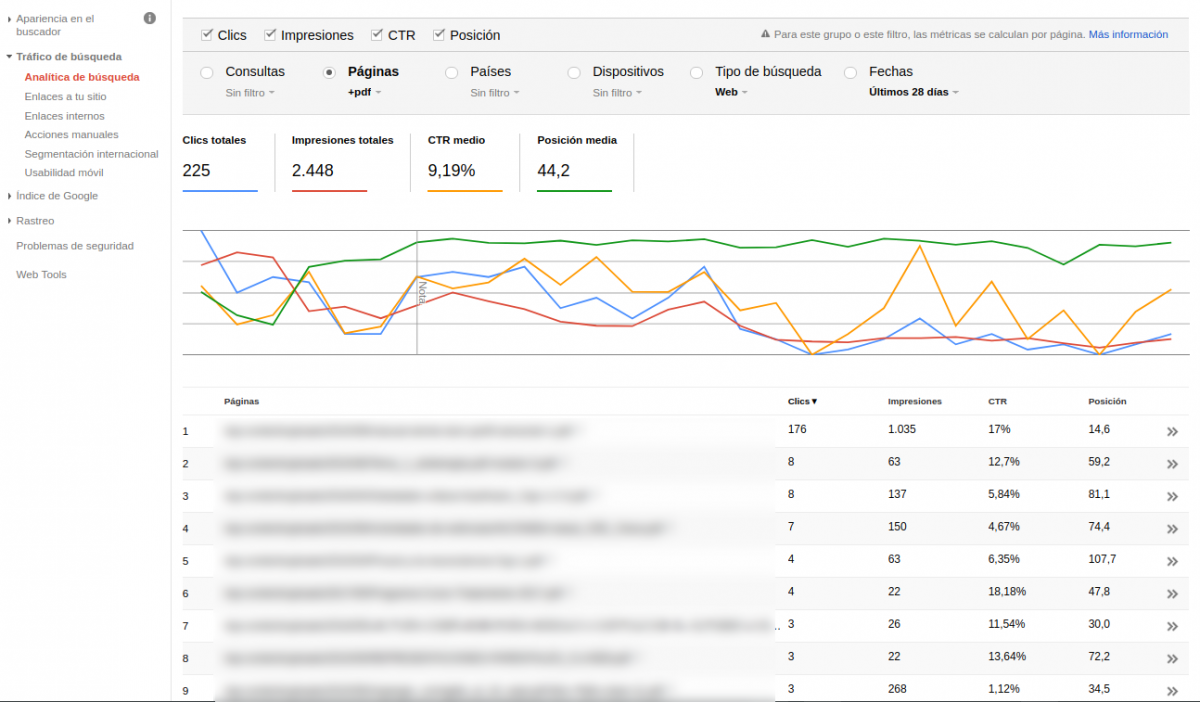
Con Search Console podemos obtener mucha información. Dentro de “Tráfico de búsqueda”, en “Analítica de búsqueda” podemos filtrar páginas que contengan PDF en sus URL: así tendremos una noción del tráfico que llega a las páginas PDF’s desde el buscador. Aquí debemos revisar si queremos bloquear todos los PDF’s o si nos interesa indexar alguno: por ejemplo, en el caso del vendedor de cursos, puede suministrarse una muestra gratuita; un sumario o una introducción.
El ping pong del software: cómo evitar el indexado de archivos PDF
Para evitar el indexamiento de archivos PDF (o de cualquier otra página de un sitio web) Google proporciona varios métodos:
- Una etiqueta meta robots no index ubicada en la sección <head> del código html del sitio:
<meta name=”robots” content=”noindex”>
Si no contamos con acceso al servidor casi siempre se puede aplicar desde el CMS que administra el sitio: esto es claramente una ventaja. El problema es que no sirve para los PDF’s porque no tienen código html.
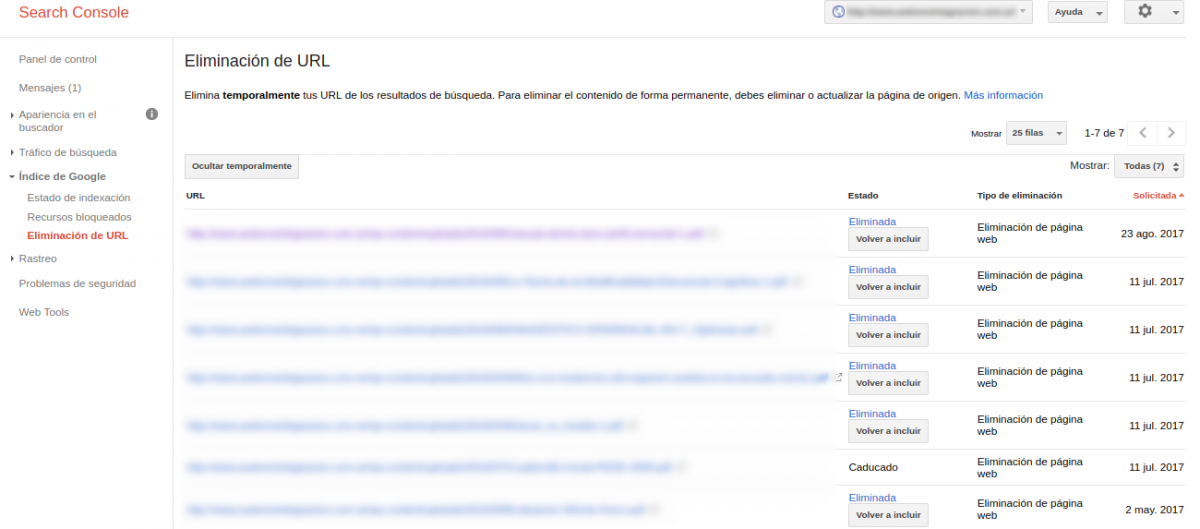
- Eliminación de URL en Search Console. Este método soluciona parcialmente el problema, pero no lo recomendamos para solucionar el problema de raíz.
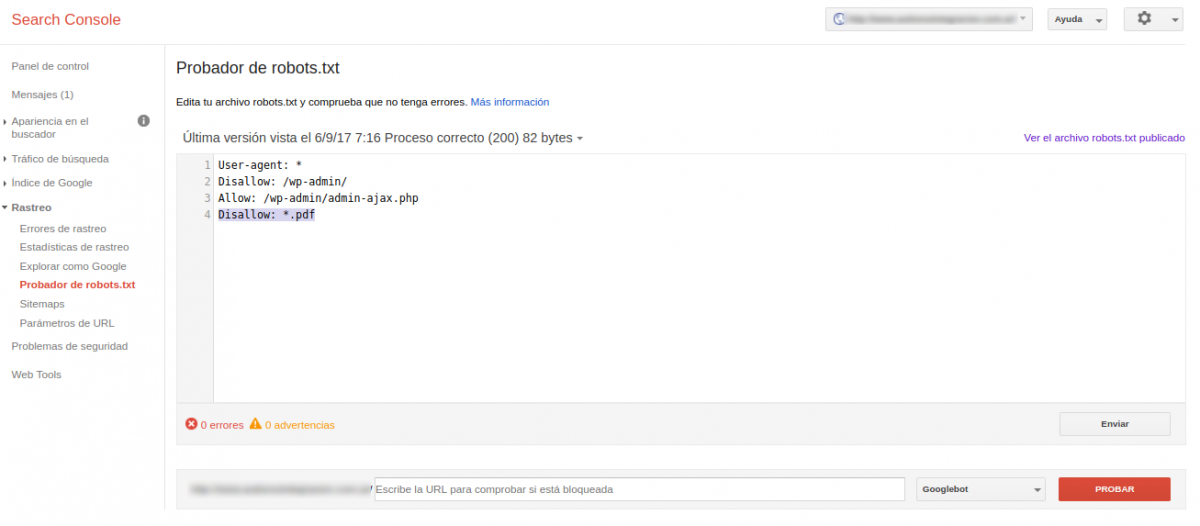
- El archivo meta robots.txt. Es simple de aplicar, sólo se necesita acceso por FTP al servidor del sitio. Dentro de Search Console existe una herramienta para probar los cambios y luego descargar el archivo final robots.txt para subir a la raíz del sitio. Simplemente agregando la línea “Disallow: *.pdf” bloqueamos el acceso del crawler.
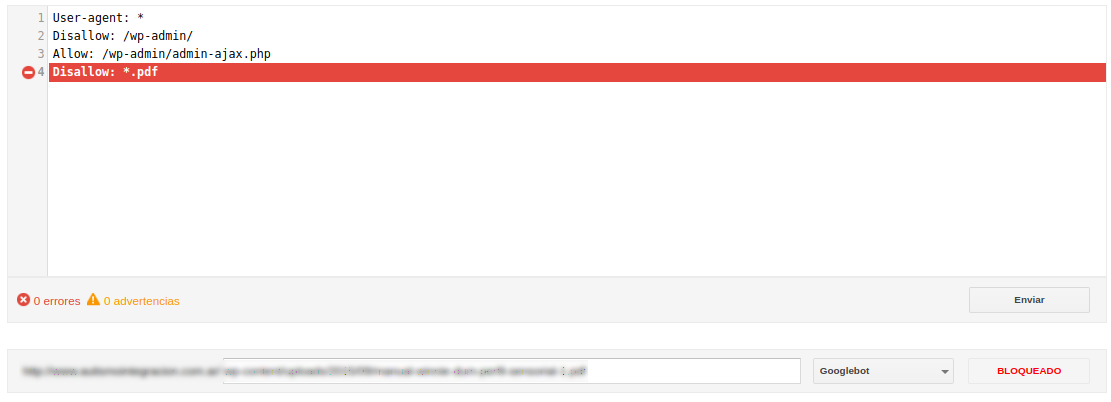
Es útil el probador para verificar con alguno de los PDF’s encontrados anteriormente:
Conclusión
Es muy recomendable revisar semanalmente en Search Console las páginas que reciben tráfico para detectar indexación no deseada. Google dedica gran cantidad de recursos para mejorar su robotito: escanea día a día el contenido de los millones de sitios web que existen. Es parte de nuestro trabajo asegurarnos de que esté yendo por buen camino.

- ¿Qué es el CTR, CPC y CPA en marketing digital?: Explicación completa - octubre 28, 2024
- Consejos para bloquear la indexación de archivos PDF - marzo 27, 2018
- ¿Eres más lento que tu página? Lee este artículo antes de julio ’18 o te pasarán como a un poste - enero 23, 2018
¿Qué te pareció este artículo?
What do you think about this post?
¡Mira también esto!





Excelente articulo!
¡Muchas gracias, David! Saludos
Buen artículo es un tema básico pero que muchos programadores de sitios que son aficionados y hace su propia programacion bien pueden no haberlo tenido en cuenta. Además me resulto entretenido de leer! Bien chicos.
Muchas gracias, Claudio! Es como bien decís: un tema básico que puede servir como repaso para expertos, o como primeros pasos para aficionados.